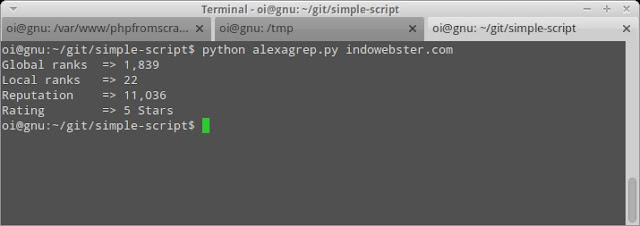
In this case i just need that information, when i looking on alexa i found so many information about the target site.
I have some knowledge about python and beautifulsoup library and i try to grep that information with them.
First time i analyzing structure of page of alexa.com, find element of html tag which contains the data.

Based on screenshot, the data on the div tag with class data, first tag is global ranks, second is local ranks and then reputation and rating. So the script must be grep a div tag with specification then do a looping.
In the source i need somes python library like sys to get arguments, urllib2 to opening url, BeautifulSoup to parsing the html, re to remove empty character which produced by BeautifulSoup output.
In the source i need somes python library like sys to get arguments, urllib2 to opening url, BeautifulSoup to parsing the html, re to remove empty character which produced by BeautifulSoup output.
Ok, this is the source to get the information.
#!/usr/bin/env python
# -*- coding: utf8 -*-
# alexagrep.py
# Ardi nooneDOTnu1ATgmailDOTcom
# GNU GPL
import sys
import urllib2
from bs4 import BeautifulSoup
from re import sub
ATTR = [
'Global ranks ',
'Local ranks ',
'Reputation ',
'Rating ',
]
def openLink(url):
_url = 'http://www.alexa.com/siteinfo/'+ url
opener = urllib2.build_opener()
opener.addheaders = [('User-agent', 'Mozilla/5.0')]
return opener.open(_url).read()
if __name__ == '__main__':
try:
url = sys.argv[1]
except:
print 'Error url'
sys.exit()
html = openLink(url)
soup = BeautifulSoup(html)
tds = soup.find('tr', {'class':'data-row1'}).findAll('td')
i=0
for td in tds:
print ATTR[i] +' => '+ sub(r'\s+', ' ', td.find('div', {'class':'data'}).text.strip())
i = i + 1
This script can be downloaded on https://github.com/emaniacs/simple-script/blob/master/alexagrep.py.
To execute script just type $ python alexagrep.py url or copying into /usr/local/bin and adding execute permission to script (chmod +x).
.

.
0 comments:
Post a Comment